

In machine learning and statistics, there is a well-known negative phenomenon called overfitting. This is when a model is so well trained on a training dataset that it becomes too specific, and as a result, is poorly applicable to new data.
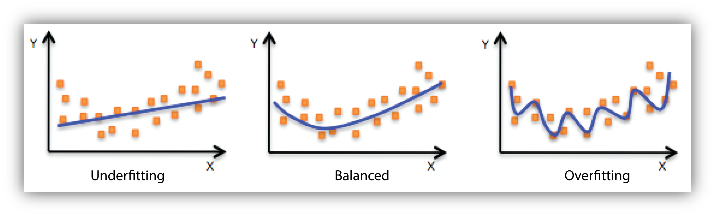
For example, an overfitted model created to visually detect product defects in manufacturing (for example, to determine the quality of brake pads – see actual project example) can detect specific patterns that are present only in a limited training sample. And start categorizing products incorrectly – good quality products are defined as having defects, and actual defects are ignored because they don’t match the specific patterns that the model found during training.
Or, using even simpler example, an overfitted human recognition model can start working in such a way that any person in a bow tie will be identified as Brad Pitt just because in the training sample only he was wearing such a tie.
How the problem of overfitting relates to the Cyber Immune approach
The problems of traditional approaches to cybersecurity are similar in nature. In the never-ending race between offense and defense, the information security industry always finds itself in the role of playing catch-up – after all, it is only pushing back against known threats. As a result, the system “adapts” to known threats and is not equipped to deal with new types of threats. And when new vulnerabilities are discovered, the holes must be patched quickly: the vendor must release a patch in time, and the system operator then has to install it as soon as possible.
The Cyber Immune approach proposes changing the rules of the game to solve this problem. It aims not just to “cover” specific vulnerabilities, but to ensure that the architecture of the solution in principle does not allow an attacker to violate the security goals of the system.
To do this, when designing a Cyber Immune system, you need to look at its architecture with a critical eye and adjust it. “Where do we have insecurities? What could potentially go wrong if a component is compromised? What needs to be changed in the architecture so that it doesn’t compromise the entire device?”
An important feature of this approach is that our initial focus is not on analyzing and protecting against all existing threats and vulnerabilities. Instead, we’re governed by Murphy’s Law: Anything that can go wrong, will go wrong. We realize that we don’t know all the vulnerabilities of a system component and all the possible attack scenarios – new ones will emerge over time – so we focus our efforts on engineering the system design to try to eliminate all of its unsafe states.
This way, the system is protected not only from known threats, but also from those that have yet to emerge.
In machine learning and statistics, there is a well-known negative phenomenon called overfitting. This is when a model is so well trained on a training dataset that it becomes too specific, and as a result, is poorly applicable to new data.
For example, an overfitted model created to visually detect product defects in manufacturing (for example, to determine the quality of brake pads – see actual project example) can detect specific patterns that are present only in a limited training sample. And start categorizing products incorrectly – good quality products are defined as having defects, and actual defects are ignored because they don’t match the specific patterns that the model found during training.
Or, using even simpler example, an overfitted human recognition model can start working in such a way that any person in a bow tie will be identified as Brad Pitt just because in the training sample only he was wearing such a tie.
How the problem of overfitting relates to the Cyber Immune approach
The problems of traditional approaches to cybersecurity are similar in nature. In the never-ending race between offense and defense, the information security industry always finds itself in the role of playing catch-up – after all, it is only pushing back against known threats. As a result, the system “adapts” to known threats and is not equipped to deal with new types of threats. And when new vulnerabilities are discovered, the holes must be patched quickly: the vendor must release a patch in time, and the system operator then has to install it as soon as possible.
The Cyber Immune approach proposes changing the rules of the game to solve this problem. It aims not just to “cover” specific vulnerabilities, but to ensure that the architecture of the solution in principle does not allow an attacker to violate the security goals of the system.
To do this, when designing a Cyber Immune system, you need to look at its architecture with a critical eye and adjust it. “Where do we have insecurities? What could potentially go wrong if a component is compromised? What needs to be changed in the architecture so that it doesn’t compromise the entire device?”
An important feature of this approach is that our initial focus is not on analyzing and protecting against all existing threats and vulnerabilities. Instead, we’re governed by Murphy’s Law: Anything that can go wrong, will go wrong. We realize that we don’t know all the vulnerabilities of a system component and all the possible attack scenarios – new ones will emerge over time – so we focus our efforts on engineering the system design to try to eliminate all of its unsafe states.
This way, the system is protected not only from known threats, but also from those that have yet to emerge.






